
 400-626-7377
400-626-7377
如何構(gòu)建一個(gè)Linux Shell(二)
在如何構(gòu)建一個(gè)Linux Shell(一)中,我們構(gòu)建了一個(gè)簡單的Linux shell,該shell打印提示字符串,讀取輸入,然后將輸入回顯到屏幕上。現(xiàn)在這不是很令人印象深刻,不是嗎?在如何構(gòu)建一個(gè)Linux Shell(二)中,我們將更新代碼,以使Shell能夠解析和執(zhí)行簡單命令。首先讓我們看一下什么是簡單的命令。

什么是簡單命令?
一個(gè)簡單的命令 由單詞列表組成,這些單詞列表由空格字符(空格,制表符,換行符)分隔。第一個(gè)單詞是命令名,并且是必需的(否則,shell將沒有解析和執(zhí)行命令!)。第二個(gè)和后續(xù)單詞是可選的。如果存在,它們形成的論點(diǎn),我們希望shell傳遞到執(zhí)行的命令。
例如,以下命令: ls -l 由兩個(gè)詞組成: ls (命令名稱),以及 -l(第一個(gè)也是唯一的參數(shù))。同樣,命令:gcc -o shell main.c prompt.c(在第一部分中,我們用它來編譯我們的shell)由5個(gè)詞組成:一個(gè)命令名和一個(gè)4個(gè)參數(shù)的列表。
為了能夠執(zhí)行簡單的命令,我們的外殼程序需要執(zhí)行以下步驟:
掃描輸入,一次輸入一個(gè)字符,以查找下一個(gè)標(biāo)記。我們稱此過程為詞法掃描,而執(zhí)行此任務(wù)的外殼部分稱為詞法掃描器,或簡稱為掃描器。
提取輸入令牌。我們稱這種標(biāo)記化輸入。
解析標(biāo)記并創(chuàng)建抽象語法樹或AST。Shell負(fù)責(zé)執(zhí)行此操作的部分稱為解析器。
執(zhí)行AST。這是執(zhí)行者的工作。
下圖顯示了Shell為了解析和執(zhí)行命令而執(zhí)行的步驟。您可以看到圖中包含的步驟比上面列表中顯示的步驟更多,這很好。隨著外殼的增長和變得越來越復(fù)雜,我們將在需要時(shí)添加其他步驟。
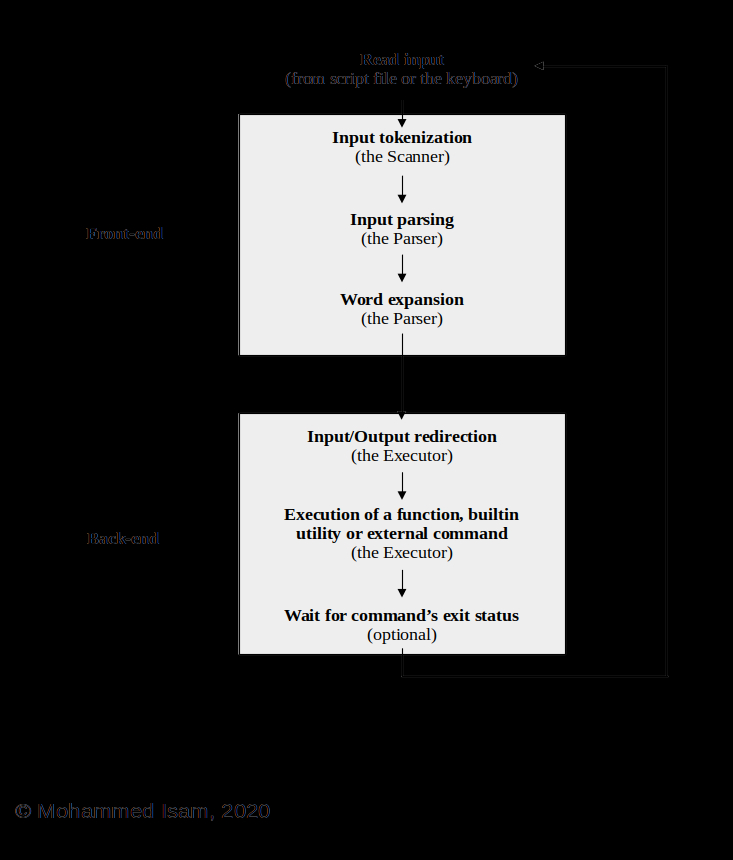
現(xiàn)在,讓我們詳細(xì)查看上述四個(gè)步驟,并查看在shell中實(shí)現(xiàn)這些功能所需的代碼。
掃描輸入
為了獲得下一個(gè)令牌,我們需要能夠一次掃描一個(gè)字符的輸入,以便我們可以識別可以作為令牌一部分的字符和作為定界符的字符。甲分隔符是一個(gè)標(biāo)記的令牌(以及可能的另一令牌的開始)的端部。通常,分隔符是空格字符(空格,制表符,換行符),但也可以包含其他字符,例如; 和 &。
通常,掃描輸入意味著我們應(yīng)該能夠:
.從輸入中檢索下一個(gè)字符。
.返回我們讀回的最后一個(gè)字符作為輸入。
.前瞻(或窺視)以檢查下一個(gè)字符,而無需實(shí)際檢索它。
.跳過空白字符。
我們將在一分鐘內(nèi)定義執(zhí)行所有這些任務(wù)的功能。但是首先,讓我們談?wù)劤橄筝斎搿?/p>
記住 read_cmd()函數(shù),這是我們在本教程的第一部分中定義的?那就是我們用來讀取用戶輸入并將其作為malloc的字符串。我們可以將此字符串直接傳遞給我們的掃描儀,但這會(huì)使掃描過程有點(diǎn)麻煩。特別是,掃描器很難記住它給我們的最后一個(gè)字符,以便它可以越過該字符并給我們后面的字符。
為了簡化掃描儀的工作,我們通過將輸入字符串作為 struct source_s 結(jié)構(gòu),我們將在源文件中定義 source.h。繼續(xù)在源目錄中創(chuàng)建該文件,然后在您喜歡的文本編輯器中將其打開并添加以下代碼:
#ifndef SOURCE_H
#define SOURCE_H
#define EOF (-1)
#define ERRCHAR ( 0)
#define INIT_SRC_POS (-2)
struct source_s
{
char *buffer; /* the input text */
long bufsize; /* size of the input text */
long curpos; /* absolute char position in source */
};
char next_char(struct source_s *src);
void unget_char(struct source_s *src);
char peek_char(struct source_s *src);
void skip_white_spaces(struct source_s *src);
#endif
關(guān)注結(jié)構(gòu)的定義,您可以看到 struct source_s 除了兩個(gè)以外,還包含指向輸入字符串的指針 long 包含有關(guān)字符串長度和我們當(dāng)前在字符串中的位置(將從中獲取下一個(gè)字符)的信息的字段。
現(xiàn)在創(chuàng)建另一個(gè)名為 source.c,您應(yīng)在其中添加以下代碼:
#include
#include "shell.h"
#include "source.h"
void unget_char(struct source_s *src)
{
if(src->curpos < 0)
{
return;
}
src->curpos--;
}
char next_char(struct source_s *src)
{
if(!src || !src->buffer)
{
errno = ENODATA;
return ERRCHAR;
}
char c1 = 0;
if(src->curpos == INIT_SRC_POS)
{
src->curpos = -1;
}
else
{
c1 = src->buffer[src->curpos];
}
if(++src->curpos >= src->bufsize)
{
src->curpos = src->bufsize;
return EOF;
}
return src->buffer[src->curpos];
}
char peek_char(struct source_s *src)
{
if(!src || !src->buffer)
{
errno = ENODATA;
return ERRCHAR;
}
long pos = src->curpos;
if(pos == INIT_SRC_POS)
{
pos++;
}
pos++;
if(pos >= src->bufsize)
{
return EOF;
}
return src->buffer[pos];
}
void skip_white_spaces(struct source_s *src)
{
char c;
if(!src || !src->buffer)
{
return;
}
while(((c = peek_char(src)) != EOF) && (c == ' ' || c == ' '))
{
next_char(src);
}
}
的 unget_char()函數(shù)將(我們從輸入中檢索到的)最后一個(gè)字符返回(或取消保護(hù))到輸入源。它只是通過操縱源結(jié)構(gòu)的指針來做到這一點(diǎn)。在本系列后面的部分中,您將看到此功能的好處。
的 next_char() 函數(shù)返回輸入的下一個(gè)字符并更新源指針,以便下一次調(diào)用 next_char()返回以下輸入字符。當(dāng)我們到達(dá)輸入中的最后一個(gè)字符時(shí),該函數(shù)將返回特殊字符EOF,我們在其中將其定義為-1 source.h 以上。
的 peek_char() 功能類似于 next_char()它返回輸入的下一個(gè)字符。唯一的區(qū)別是peek_char() 不會(huì)更新源指針,因此下一次調(diào)用 next_char()返回我們剛剛偷看的相同輸入字符。在本系列的后面部分,您將看到輸入偷看的好處。
最后, skip_white_spaces()函數(shù)將跳過所有空格字符。這將在完成讀取令牌后為我們提供幫助,并且在讀取下一個(gè)令牌之前希望跳過定界符空白。
標(biāo)記輸入
現(xiàn)在我們已經(jīng)有了掃描儀的功能,我們將使用這些功能來提取輸入令牌。我們將首先定義一個(gè)新結(jié)構(gòu),該結(jié)構(gòu)將用于表示令牌。
繼續(xù)創(chuàng)建一個(gè)名為 scanner.h 在您的源目錄中,然后將其打開并添加以下代碼:
#ifndef SCANNER_H
#define SCANNER_H
struct token_s
{
struct source_s *src; /* source of input */
int text_len; /* length of token text */
char *text; /* token text */
};
/* the special EOF token, which indicates the end of input */
extern struct token_s eof_token;
struct token_s *tokenize(struct source_s *src);
void free_token(struct token_s *tok);
#endif
專注于結(jié)構(gòu)定義, struct token_s 包含一個(gè)指向 struct source_s保留了我們的投入。該結(jié)構(gòu)還包含一個(gè)指向令牌文本的指針,以及一個(gè)告訴我們該文本長度的字段(這樣我們就無需重復(fù)調(diào)用strlen() 在令牌的文本上)。
接下來,我們將編寫 tokenize()函數(shù),它將從輸入中檢索下一個(gè)標(biāo)記。我們還將編寫一些幫助程序功能,以幫助我們使用輸入令牌。
在源目錄中,創(chuàng)建一個(gè)名為 scanner.c,然后輸入以下代碼:
#include
#include
#include
#include
#include "shell.h"
#include "scanner.h"
#include "source.h"
char *tok_buf = NULL;
int tok_bufsize = 0;
int tok_bufindex = -1;
/* special token to indicate end of input */
struct token_s eof_token =
{
.text_len = 0,
};
void add_to_buf(char c)
{
tok_buf[tok_bufindex++] = c;
if(tok_bufindex >= tok_bufsize)
{
char *tmp = realloc(tok_buf, tok_bufsize*2);
if(!tmp)
{
errno = ENOMEM;
return;
}
tok_buf = tmp;
tok_bufsize *= 2;
}
}
struct token_s *create_token(char *str)
{
struct token_s *tok = malloc(sizeof(struct token_s));
if(!tok)
{
return NULL;
}
memset(tok, 0, sizeof(struct token_s));
tok->text_len = strlen(str);
char *nstr = malloc(tok->text_len+1);
if(!nstr)
{
free(tok);
return NULL;
}
strcpy(nstr, str);
tok->text = nstr;
return tok;
}
void free_token(struct token_s *tok)
{
if(tok->text)
{
free(tok->text);
}
free(tok);
}
struct token_s *tokenize(struct source_s *src)
{
int endloop = 0;
if(!src || !src->buffer || !src->bufsize)
{
errno = ENODATA;
return &eof_token;
}
if(!tok_buf)
{
tok_bufsize = 1024;
tok_buf = malloc(tok_bufsize);
if(!tok_buf)
{
errno = ENOMEM;
return &eof_token;
}
}
tok_bufindex = 0;
tok_buf[0] = ' 主站蜘蛛池模板: 国产精品夜夜春夜夜爽久久老牛 | 日本一区二区久久精品 | 亚洲人成未满十八禁网站 | yy6080午夜 | 日本巨大的奶头在线观看 | 欧美日韩激情视频一区二区三区 | 少妇大叫又粗又大太爽A片 久久人人爽亚洲精品天堂 粉嫩一区二区三区 | 国产剧情av一区二区三区在线观看 | 国产一线产区二线产区 | 五十度灰2在线观看 | 一区二区三区在线视频免费观看 | 国产欧美日韩精品第二区 | 偷拍超碰 | 国产午夜一级在线观看影院 | 久久精品性 | 久久的爱久久的你在线观看 | 日本特黄特色a大片免费高清观看视频 | 在线一二区 | 日韩视频www| 国产精品第一区 | av在线一级| AV无码一区二区二三区1区6区 | 精品久久a | av成人免费 | chinese中国女人高潮 | 中国少妇饥渴XXXXX | 公交车上~嗯啊被高潮视频软件 | 日韩视频中文 | 国产精品91一区二区 | 亚洲中文字幕美腿 | 欧美日韩精品不卡一区二区三区 | 99热这里只有精品地址 | 最近中文字幕在线视频1 | 啦啦啦中文在线视频免费观看 | 日本精品免费看 | 无码精品AV久久久奶水小说 | 中文字幕a∨在线乱码免费看 | 99久久影视| 精品视频1区2区 | xxxxx免费视频 | 91色综合网|